Multi-GPU Training with PyTorch: Distributed Data Parallel (DDP)
This was adapted from Princeton University Multi-GPU Training with PyTorch
One should always first try to use only a single GPU for training. This maximizes efficiency. There are two common reasons for using multiple GPUs when training neural networks:
- the execution time is too long with a single GPU
- the model is too large to fit on a single GPU
The more GPUs you request for a Slurm job, the longer the queue time will be. Learn how to conduct a scaling analysis to find the optimal number of GPUs.
Overall Idea of Distributed Data Parallel
The single-program, multiple data (SPMD) paradigm is used. That is, the model is copied to each of the GPUs. The input data is divided between the GPUs evenly. After the gradients have been computed they are averaged across all the GPUs. This is done in a way that all replicas have numerically identical values for the average gradients. The weights are then updated and once again they are identical by construction. The process then repeats with new mini-batches sent to the GPUs.
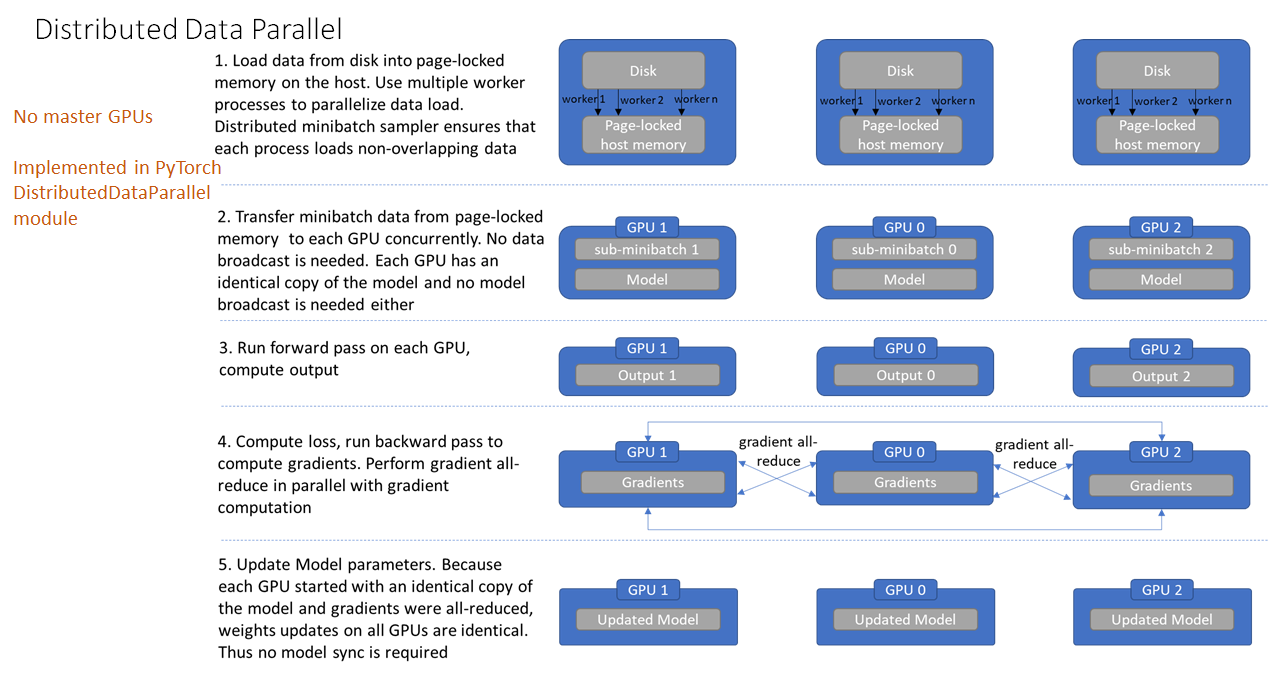
Credit for the image above is here.
If you would like more background then read through these PyTorch pages:
Here are some webpages and videos:
Do not use DataParallel in PyTorch for anything since it gives poor performance relative to DistributedDataParallel.
Main changes needed in going from single-GPU to multi-GPU training with DDP
This completely new piece is needed to form the process group:
def setup(rank, world_size):
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
Note that dist.init_process_group() is blocking. That means the code waits until all processes have reached that line and the command is successfully executed before going on. One should prefer nccl over gloo since the latter will use TCP by first moving tensor to CPU.
For the single-GPU training:
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
For multi-GPU training with DPP:
model = Net().to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank])
optimizer = optim.Adadelta(ddp_model.parameters(), lr=args.lr)
More on local_rank below. In short, this is the GPU index.
One also needs to ensure that a different batch is sent to each GPU:
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset1, num_replicas=world_size, rank=rank)
train_loader = torch.utils.data.DataLoader(dataset1, batch_size=args.batch_size, sampler=train_sampler, \
num_workers=int(os.environ["SLURM_CPUS_PER_TASK"]), pin_memory=True)
Simple DDP Script
The following can be used as a simple use case of DPP:
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from socket import gethostname
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Linear(42, 3)
def forward(self, x):
x = self.fc(x)
x = F.relu(x)
output = F.log_softmax(x, dim=1)
return output
rank = int(os.environ["SLURM_PROCID"])
world_size = int(os.environ["WORLD_SIZE"])
gpus_per_node = int(os.environ["SLURM_GPUS_ON_NODE"])
assert gpus_per_node == torch.cuda.device_count()
print(f"Hello from rank {rank} of {world_size} on {gethostname()} where there are" \
f" {gpus_per_node} allocated GPUs per node.", flush=True)
dist.init_process_group("nccl", rank=rank, world_size=world_size)
if rank == 0: print(f"Group initialized? {dist.is_initialized()}", flush=True)
local_rank = rank - gpus_per_node * (rank // gpus_per_node)
torch.cuda.set_device(local_rank)
model = Net().to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank])
ddp_model.eval()
with torch.no_grad():
data = torch.rand(1, 42)
data = data.to(local_rank)
output = ddp_model(data)
print(f"host: {gethostname()}, rank: {rank}, output: {output}")
dist.destroy_process_group()
SLURM_PROCID is a Slurm environment variable and it varies from 0 to N - 1, where N is the number of tasks running under srun. For instance, consider the abbreviated Slurm script below:
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=4
...
srun python myscript.py
The Python interpreter will be launched 8 times (2 x 4) and each of the 8 tasks will have a different value of SLURM_PROCID from
the set 0, 1, 2, 3, 4, 5, 6, 7.
Below is a full Slurm script for using DDP for Della (GPU) where there are 2 GPUs per node:
run-full.SBATCH:
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=2
#SBATCH --time=1:00:00
#SBATCH --mem=2GB
#SBATCH --gres=gpu:2
#SBATCH --job-name=torch
module purge
export MASTER_ADDR=$(hostname)
export MASTER_PORT=12345
export WORLD_SIZE=$SLURM_NTASKS
export RANK=$SLURM_PROCID
srun singularity exec --nv \
--overlay /scratch/NetID/pytorch-example/my_pytorch.ext3:ro \
/scratch/work/public/singularity/cuda12.1.1-cudnn8.9.0-devel-ubuntu22.04.2.sif\
/bin/bash -c "source /ext3/env.sh; python simple_ddp.py"
In the script above, MASTER_PORT, MASTER_ADDR and WORLD_SIZE are set. The three are later used to create the DDP process group. The total number of GPUs allocated to the job must be equal to WORLD_SIZE -- this is satisfied above since nodes times ntasks-per-node is 2 x 2 = 4 and number of GPUs allocated is nodes times gpus_per_node which is also 2 x 2 = 4.
This uses the overlay file for PyTorch we created in Singularity with Conda
Job Arrays
For a job array, all jobs of the array have the same value of SLURM_JOBID. Because of this, it is wise to modify MASTER_PORT.
Here is one possibility:
export MASTER_PORT=$(expr 10000 + $(echo -n $SLURM_JOBID | tail -c 4) + $SLURM_ARRAY_TASK_ID)
--ntasks-per-node versus --ntasks
Be sure to use --ntasks-per-node and not --ntasks in your Slurm script.
What is local_rank?
The indices of the GPUs on each node of your Slurm allocation begin at 0 and end at N - 1, where N is the total number of GPUs in your allocation on each node. Consider the case of 2 nodes and 8 tasks with 4 GPUs per node. The process ranks will be 0, 1, 2, 3 on the first node and 4, 5, 6, 7 on the second node while the GPU indices will be 0, 1, 2, 3 on the first and 0, 1, 2, 3 on the second. Thus, one cannot make calls such as data.to(rank) since this will fail on the second node where there is a mismatch between the process ranks and the GPU indices. To deal with this a local rank is introduced:
rank = int(os.environ["SLURM_PROCID"])
gpus_per_node = int(os.environ["SLURM_GPUS_ON_NODE"])
local_rank = rank - gpus_per_node * (rank // gpus_per_node)
The local_rank should be used everywhere in your script except when initializing the DDP process group where rank should be used. In Python, one uses the // operator for integer division. For example, 1 / 2 = 0.5 while 1 // 2 = 0.
DDP and Slurm
Total number of tasks equals total number of GPUs
When using DDP, the total number of tasks must equal the total number of allocated GPUs. Therefore, if --ntasks-per-node=<N> then you must have --gres=gpu:<N>. Here are two examples:
#SBATCH --ntasks-per-node=2
#SBATCH --gres=gpu:2
#SBATCH --ntasks-per-node=4
#SBATCH --gres=gpu:4
You should take all of the GPUs on a node before going to multiple nodes. Never do one GPU per node for multinode jobs.
Full Example of DDP
Below is an example Slurm script for DDP:
#!/bin/bash
#SBATCH --job-name=ddp-torch # create a short name for your job
#SBATCH --nodes=2 # node count
#SBATCH --ntasks-per-node=2 # total number of tasks per node
#SBATCH --cpus-per-task=8 # cpu-cores per task (>1 if multi-threaded tasks)
#SBATCH --mem=32G # total memory per node (4 GB per cpu-core is default)
#SBATCH --gres=gpu:2 # number of gpus per node
#SBATCH --time=00:05:00 # total run time limit (HH:MM:SS)
export MASTER_PORT=$(expr 10000 + $(echo -n $SLURM_JOBID | tail -c 4))
export WORLD_SIZE=$(($SLURM_NNODES * $SLURM_NTASKS_PER_NODE))
echo "WORLD_SIZE="$WORLD_SIZE
master_addr=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_ADDR=$master_addr
echo "MASTER_ADDR="$MASTER_ADDR
srun singularity exec --nv \
--overlay /scratch/NetID/pytorch-example/my_pytorch.ext3:ro \
/scratch/work/public/singularity/cuda12.1.1-cudnn8.9.0-devel-ubuntu22.04.2.sif\
/bin/bash -c "source /ext3/env.sh; python download_data.py; python mnist_classify_ddp.py --epoch
s=2"
The script above uses 2 nodes with 2 tasks per node and therefore 2 GPUs per node. This yields a total of 4 processes and each process can use 8 CPU-cores for data loading. An allocation of 4 GPUs is substantial so the queue time may be long. In all cases make sure that the GPUs are being used efficiently by monitoring the GPU utilization.
Below is the original single-GPU Python script modified to use DDP:
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import os
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from socket import gethostname
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def setup(rank, world_size):
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': int(os.environ["SLURM_CPUS_PER_TASK"]),
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('data', train=True, download=False,
transform=transform)
dataset2 = datasets.MNIST('data', train=False,
transform=transform)
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["SLURM_PROCID"])
gpus_per_node = int(os.environ["SLURM_GPUS_ON_NODE"])
assert gpus_per_node == torch.cuda.device_count()
print(f"Hello from rank {rank} of {world_size} on {gethostname()} where there are" \
f" {gpus_per_node} allocated GPUs per node.", flush=True)
setup(rank, world_size)
if rank == 0: print(f"Group initialized? {dist.is_initialized()}", flush=True)
local_rank = rank - gpus_per_node * (rank // gpus_per_node)
torch.cuda.set_device(local_rank)
print(f"host: {gethostname()}, rank: {rank}, local_rank: {local_rank}")
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset1, num_replicas=world_size, rank=rank)
train_loader = torch.utils.data.DataLoader(dataset1, batch_size=args.batch_size, sampler=train_sampler, \
num_workers=int(os.environ["SLURM_CPUS_PER_TASK"]), pin_memory=True)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(local_rank)
ddp_model = DDP(model, device_ids=[local_rank])
optimizer = optim.Adadelta(ddp_model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, ddp_model, local_rank, train_loader, optimizer, epoch)
if rank == 0: test(ddp_model, local_rank, test_loader)
scheduler.step()
if args.save_model and rank == 0:
torch.save(model.state_dict(), "mnist_cnn.pt")
dist.destroy_process_group()
if __name__ == '__main__':
main()
In the script above the number of workers is taken directly from the value of --cpus-per-task which is set in the Slurm script:
cuda_kwargs = {'num_workers': int(os.environ["SLURM_CPUS_PER_TASK"]), 'pin_memory': True, 'shuffle': True}
It also relies on the script download_data.py:
import torchvision
import warnings
warnings.simplefilter("ignore")
# compute nodes do not have internet so download the data in advance
_ = torchvision.datasets.MNIST(root='data',
train=True,
transform=None,
target_transform=None,
download=True)
Execute the commands below to run the example above:
[NetID@log-1 full-ddp-test]$ sbatch run-full.SBATCH
Memory issues
Use gradient_as_bucket_view=True when making the DDP model to decrease the required memory by 1/3.